Title: O Processo Hidra
Author: Silvio Rhatto
Generator: S9
%css
body {
font-family: monospace;
}
.centered img {
display: block;
margin-left: auto;
margin-right: auto;
}
.centered {
text-align: center;
}
p, li, dt, dd, td, th {
font-size: 16pt;
}
.slide h1 {
font-size: 25pt;
}
%end
!SLIDE centered

O Processo Hidra
================

De relógios a nuvens, de nuvens a hidras.
Parte 1: Introdução
===================
Objetivo da apresentação
========================
O objetivo desta fala é divulgar os estudos em andamento sobre o processo hidra dando espaço para possíveis andamentos:
1. Informar os grupos e pessoas que possuem conteúdo hospedado em infraestruturas tecno-sociais comuns sobre o trabalho desenvolvido.
2. Encorajar grupos técnicos existentes para adotarem procedimentos que favoreçam suas infraestruturas a terem comportamento hidra.
Esta apresentação ainda está em processo de concepção e revisão e por isso não está sendo divulgada.
O que é uma Hidra?
==================
Ser mitológico de múltiplas cabeças regenerativas, destruído por Hércules
=========================================================================

Na biologia moderna, animal aquático que possui capacidades regenerativas
=========================================================================
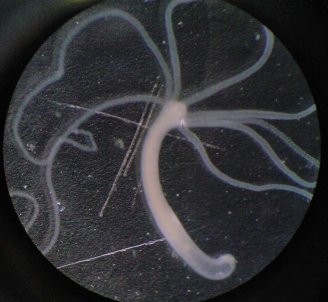
O que é o Processo Hidra?
=========================
O Processo Hidra é uma descrição de infraestruturas tecno-sociais que apresentam:
1. Replicabilidade e escalabilidade.
2. Capacidade de combinação rizomática.
3. Regeneração e reagrupamento após eventos catastróficos.
A Hidra moderna pode resistir a Hércules.
Parte 2: Grupos Técnicos Sociais
================================
Mas antes façamos uma retrospectiva...
Sistemas informacionais sociais
===============================
Modelo "clássico" de hospedagem: arquitetura "cliente-servidor":

Trabalho técnico informacional em grupos sociais
================================================
Características:
- Considerado tecnicamente de alta dificuldade e dedicação.
- Esforço para provisionamento, configuração e manutenção de sistemas.
- Trabalho demorado: escala de meses para alcançar estabilidade.
- Suscetível a muitas falhas: escala de horas para que um sistema seja inutilizado.
- Pouco tempo disponível para o trabalho.
- Dificuldade para a realização de backups e manutenção de procedimentos administrativos.
- Baixa mobilização e força de trabalho "tarefeira".
- Custa um bom dinheiro...
Interlúdio: a destruição das redes
==================================
A cada evento catastrófico, vários grupos são prejudicados com danos à comunicação de difícil cicatrização.
Parte 3: Contra-ataque infraestrutural
======================================
Como impedir que uma rede seja destruída mesmo que a remoção de nodos continue?
A divisão em camadas
====================
Observação crucial:
"Ghost in the shell": o disco e o hardware são intercambiáveis,
provisionamento pode ocorrer em múltiplas etapas. É possível
manter um estoque de discos pré-instalados e uma reserva financeira
para a aquisição de máquinas. Isso e backups permite a reconstrução
de sistemas.
Conclusão imediata:
É necessário "descolar" a camada de serviços (web, streaming, email,
etc) da camada infraestrutural (máquinas, conexões, etc): filtragem
de problemas físicos e jurídicos.
A camada de serviços pode então ser "congelada" na forma de backups, enquanto que a camada infraestrutural não possui "alma" intrínseca, podendo ser reconfigurada quando necessário. Desse modo, várias máquinas podem ser mantidas no ar para aumentar a tolerância a falhas.
Mas como um sítio pode estar simultaneamente em várias máquinas?
DNS: colando domínios em máquinas
=================================
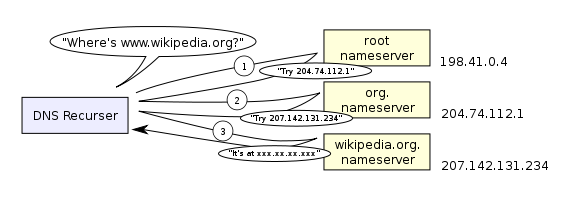

O colamento/descolamento entre camadas é possível mediante mudanças de DNS.
Proxies: distribuindo um sítio entre máquinas
=============================================
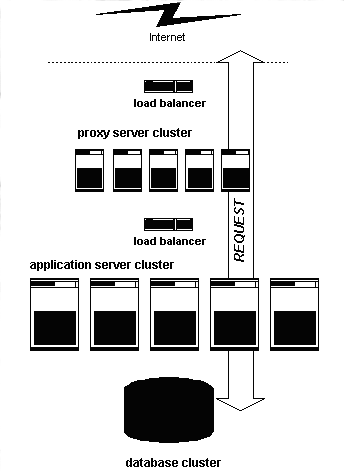
Aplicação descentralizada ou distribuída
========================================

Tipos de camadas
================
Informação de um sistema é dividida conforme sua aplicabilidade:
- Hardware: manifestações cristalizadas de informação: computadores.
- Programas (software): pacotes.
- Configuração (módulos).
- Chaves e senhas.
- Dados (o conteúdo propriamente dito).
Tais camadas podem ser empacotadas em sistemas e tais sistemas podem ser agregados em outros sistemas (camadas de camadas de camadas): pode ser uma abstração complicada, mas o ganho conceitual em isolamento de instâncias é importante.
Problemas
=========
O discurso é bonito, porém...
1. Hardware é muito heterogêneo para padronizações serem efetivas.
2. Os programas são muito diversos para serem estudados, integrados e desenvolvidos.
3. Configurações são muito complexas e numerosas para serem facilmente separadas e replicadas de forma genérica.
4. São necessárias muitas senhas de boa complexidade, o que torna sua manutenção complicada.
5. Backups são difíceis de serem realizados e recuperados.
Ou seja: o discurso da divisão em camadas é interessante, porém na realidade sua implementação enfrenta diversos problemas. Serão eles impeditivos?
O Plano R*
==========
O Plano R*: email
=================
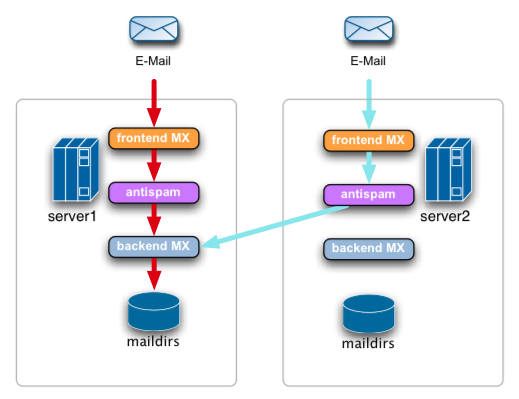
Como é possível?
================
O segredo está na articulação da força de trabalho com a divisão de camadas. A regra geral é:
1. Utilização de ferramentas sólidas e amplamente utilizadas por comunidades de software livre e aberto.
2. Trabalho de desenvolvimento focado na integração de soluções existentes, enviando alterações em código corrente acima sempre que possível.
3. Desenvolvendo código próprio, porém livre, apenas quando não existente ou insuficiente nas comunidades.
Cada um desdes tipos informacionais é distribuído em unidades que por sua vez são agregados em árvores:
- Hardware em servidores (canalizadores de fluxos, nodos ou instâncias em nuvens).
- Programas em pacotes e distribuições.
- Configurações em módulos e repositórios.
- Chaves (que são unidades de segredo) em repositórios.
- Dados em árvore de backups.
Divisão artefática
==================
A divisão em camadas é artificial (artefática), porém com importantes consequências quando observada à luz da divisão do trabalho de comunidades de software livre e aberto:
/'\ |
| \./
upstream downstream
- Hardware: desenvolvimento caro e complexo; hardware livre e aberto engatinhando; dependência do mercado. Exemplo: disco rígido.
- Programas e distribuições: grandes comunidades de desenvolvimento e uso. Exemplo: GNU/Linux, Debian.
- Configuração: comunidades mais restritas de desenvolvimento e uso. Exemplo: manuais, howtos, módulos.
- Chaves e senhas: restrita ao grupo responsável por manter uma dada infraestrutura. Exemplo: senha de superusuário/a.
- Dados: desenvolvidos pelas pessoas e grupos hospedados. Exemplo: texto num wiki.
Divisão artefática - 2
======================
É possível reconstruir um sistema dados esses elementos. A divisão do trabalho upstream/downstream é favorável à reconstrução, já que as tarefas se tornam mais complexas ao longo da subida da corrente onde usualmente os grandes grupos sociais se reúnem para solucioná-las.
Economia de trabalho
====================
Assim, é possível economizar muita força de trabalho.
1. Enviar um desenvolvimento corrente acima (upstream) libera o grupo técnico de uma manutenção posterior, pois o trabalho passa a ser de responsabilidade da comunidades mais ampla.
2. Quanto mais específica for a informação, mais abaixo da corrente (downstream) ela deve ser mantida.
3. Naquilo que não houver desenvolvimento corrente acima, atuar como fonte (ou seja, agir como upstream) e fornecer para a comunidade.
Tipos de salvaguarda
====================
Para todas as camadas divididas anteriormente é possível criar algum tipo de salvaguarda contra perdas:
- Dinheiro: armazenamento e replicação de força de trabalho (potencial de trabalho armazenado).
- Estoque: hardware hoje é commodity, podendo ser minimamente estocado ou mantido online em diversos locais.
- Repositórios: programas, pacotes, distribuições e configurações.
- Backups: manutenção de dados ou coisas sobressalentes.
Parte 3: contexto brasileiro
============================
Orçamento e infraestrutura
==========================
Custos:
- Plano R*: EUR 10.000 anuais.
- No Brasil, é praticamente a despesa anual de um centro social alugado e muito mais do que a receita da maioria dos grupos.
Conexão:
- Nos EUA e na Europa, a conexão é rápida e barata. Datacenters corporativos são acessíveis.
- No Brasil, a conexão é lenta, cara e o preço dos datacenters é exorbitante.
Repressão:
- Criminalização dos movimentos sociais (entulho jurídico).
- Polícia violenta.
Estaremos impossibilitados/as de mantermos servidores no país?
Por outro lado
==============
- A legislação, a jurisprudência, cultura e valores brasileiros são muito mais favoráveis à preservação da privacidade que nos EUA ou na Europa (fator Dantas).
- Honorários advocatícios não são tão altos quanto no exterior (?).
- O câmbio é favorável a doações internacionais.
O caso Satangoss
================
"O que demorou quatro anos para juntarmos nos foi arrebatado num único dia."
- Agosto de 2008: polícia civil apreende o servidor do Saravá sem mandado judicial.
- Mais de cem sítios fora do ar.
- Não havia backup remoto e nem medidas de contingência estabelecidas.
- Todos os ovos estavam na mesma cesta.
- Grande desmobilização.
- Análise do caso: http://www.sarava.org/node/44
Como reverter a crise num novo ciclo de mudança e amadurecimento?
Parte 4: O Processo Hidra
=========================
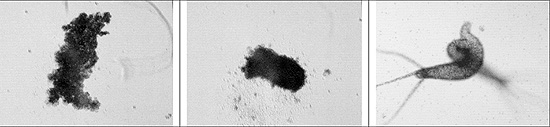
Regeneração
===========
Hidra: toda célula pode ter o germe da própria organização. Múltiplas cabeças, células tronco que podem adquirir especialização conforme a necessidade.

Hidra em processo
=================

Hidra em processo - 2
=====================

%% Hidra em processo - 3
%% =====================
%%
%%
%%
%%Fonte: http://odelberglab.genetics.utah.edu/regen_mech.htm
%% Arredondamento de aglomerados celulares:
%% ========================================
%%
%% http://hal.archives-ouvertes.fr/docs/00/02/92/51/PDF/rounding_revised.pdf
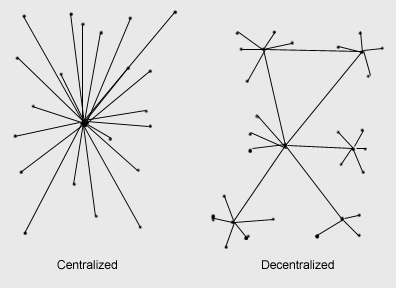
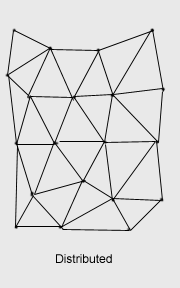
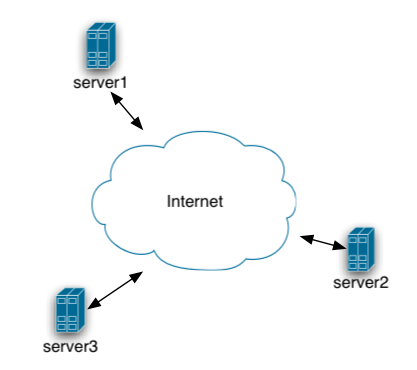
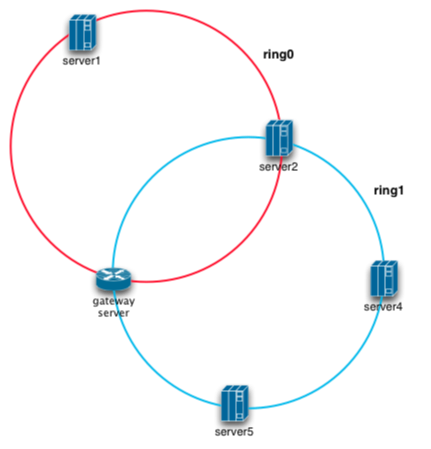
Topologias
==========
"[To] keep our sources safe, we have had to spread assets, encrypt everything,
and move telecommunications and people around the world to activate protective
laws in different national jurisdictions," Mr Assange said told the BBC earlier
this year.
Fonte: [http://www.bbc.co.uk/news/world-11047811](http://www.bbc.co.uk/news/world-11047811)
Possíveis montagens: anel, estrela, rizomática, etc. Frontends e backends.
Parte 5: O Processo Hidra Saravento
===================================
1. Apresenta Padrão Saravá (Sarava Pattern, [http://padrao.sarava.org](http://padrao.sarava.org)).
2. Utiliza Resource Sharing Protocol (RSP, [http://rsp.sarava.org](http://rsp.sarava.org)).
3. Considerando a adoção de padrões definidos de política de segurança e privacidade.
4. Organiza-se de acordo com protocolos ([http://protocolos.sarava.org](http://protocolos.sarava.org)).
Na Hidra Saraventa, cada célula é chamada de "nodo":
- Nodos físicos com servidores virtuais com fins específicos.
- Nodos virtuais em diversos locais (inclusive hospedados por terceiros).
Baseada no seguinte pricípio: quais problemas solucionaremos, quais não.
O Padrão Saravá
===============
O Padrão Saravá é uma sistematização de configuração de servidores, gerenciadores de conteúdo e aplicações diversas usados pelo Grupo Saravá. O padrão foi desenvolvido para:
- Ter controle dos pacotes utilizados, arquivos de configuração e serviços em uso.
- Uniformidade de administração.
- Sistema de gerenciamento de backups comum para que as máquinas de um projeto possam trocar dados.
- Que um servidor seja configurado apenas uma vez e que suas configurações possam ser aproveitados para outras máquinas.
- Que sites e serviços sejam armazenados de maneira regular para facilitar atualizações e migrações.
- Manter projetos e serviços isolados uns dos outros através de servidores virtuais.
- Tornar a instalação dos servidores facilmente replicável.
Dinâmica de desenvolvimento:
Documentação wiki -> Configurações pré-gravadas -> Software
Puppet
======


Puppet: compartilhando configuração
===================================
Código puppet:
file { '/etc/passwd':
owner => root,
group => root,
mode => 644,
}
Módulos compartilhados:
- [http://git.sarava.org](http://git.sarava.org)
- [https://labs.riseup.net/code/projects/sharedpuppetmodules](https://labs.riseup.net/code/projects/sharedpuppetmodules)
Git e gitosis
=============


O Protocolo de Compartilhamento de Recursos
===========================================
"The Resource Sharing Protocol (RSP) is a set of metadata intended to help free
software groups
* Share their available resources and also Find groups that can host
* services for them given their needs and requirements.
The RSP splits each resource in a layer or set of service layers. You can think
of service layers something very general, ranging from servers, databases,
websites. If you need to, you can even consider stuff such as tables and
bicycles as layers that provide some kind of service to a hosted group. ;)"
-- http://rsp.sarava.org
Orquestração
============
Para complementar a Configuração de sistemas padronizada e centralizada, procedimentos como
1. Atualização de pacotes.
2. Atualização de código de gerenciadores de conteúdo.
3. Carga de bancos de dados.
podem ser codificados de forma a serem facilmente aplicados a múltiplas camadas de forma simultânea.
Exemplos:
- [https://git.sarava.org/?p=hydra.git;a=summary](https://git.sarava.org/?p=hydra.git;a=summary)
- [http://www.capify.org](http://www.capify.org)
- [http://marionette-collective.org](http://marionette-collective.org)
- [https://fedorahosted.org/func](https://fedorahosted.org/func)
- [http://fabfile.org](http://fabfile.org)
- [http://www.debian-administration.org/article/Automating_ssh_and_scp_across_multiple_hosts](http://www.debian-administration.org/article/Automating_ssh_and_scp_across_multiple_hosts)
Ikiwiki
=======
O Ikiwiki ([http://ikiwiki.info](http://ikiwiki.info)) é um software de wiki que usa um sistema de controle de versão e arquivos de texto, possibilitando:
1. A existência de múltiplas cópias integrais do wiki (online e offline).
2. Desenvolvimento distribuído de documentação.
O ikiwiki é muito útil para reunir documentação de sistemas, já que não necessita de nenhum sistema web funcional para abrigá-la.
Virtualização
=============
Virtualização através de Linux-VServer (existem outras implementações possíveis):
- [http://www.linux-vserver.org](http://www.linux-vserver.org)
- [http://slack.sarava.org/vservers](http://slack.sarava.org/vservers)
Principais vantagens:
- Permite diversos grupos compartilharem uma mesma máquina presevando sua autonomia.
- Grupos podem hospedar mutuamente instâncias virtuais. Exemplo: se existem 5 grupos com uma máquina cada um, se cada um deles hospedar um vserver para cada grupo, teremos 4 locais remotos de hospedagem por grupo, aumentando assim as possibilidades de salvaguarda e escalabilidade.
Keyringer e monkeysphere
========================
O Keyringer ([http://git.sarava.org/?p=keyringer.git;a=summary](http://git.sarava.org/?p=keyringer.git;a=summary)) é um repositório distribuído de senhas/chaves baseado em GPG e git.
O monkeysphere ([http://web.monkeysphere.info](http://web.monkeysphere.info)) é um programa que permite a verificação de hosts SSH e usuários/as através da Teia de Confiabilidade do OpenPGP. Com ele, o gerenciamento de fingerprints fica mais fácil e evita que páginas como esta centralizem informações que possam se desatualizar.
Tecnologia bootless
===================
Muitos esquemas de criptografia em disco se baseiam na proteção das partições de dadados e da área de troca, porém dependem da existência de ao menos uma partição de inicialização com as imagens do sistema e de um setor de inicialização.
Com acesso físico à máquina, é possível infectar tais dados de inicialização e comprometer a criptografia de todo o sistema.
Para mitigar a situação, o esquema Bootless é um repositório git que contém as imagens de inicialização e a configuração necessárias para o procedimento de partida.
Assim, é possível manter a parte de inicialização fora da máquina, por exemplo em chaveiros USB.
Projeto similar: [http://lfde.org](http://lfde.org)
Monitoramento: nagios
=====================
Monitoramento: munin
====================

%%
%%Fonte: [http://exchange.munin-monitoring.org/plugins/icecast2/details](http://exchange.munin-monitoring.org/plugins/icecast2/details)
Backups
=======
Estratégia:
1. Backups locais criptografados com duplicity:
- Incluindo apenas `/etc`, `/var`, `/home`.
- Excluindo logs, cache e backups remotos.
2. Backups remotos apenas do backup local em duplicity, via rdiff ou rsync.
3. Nodos designados para armazenamento de backups.
4. Incrementos locais e remotos para aumentar consistência dos dados.
5. Procedimento integrado de restore e ativação de nodo.
Hardware e custos
=================
- Servidor mini-ITX Atom dual core + 2GB RAM + 1TB: R$680.00.
- Nobreaks APC: +/- R$500,00.
- Banda larga ADSL/cabo: R$80,00 a R$200,00.
- Energia: 180W (mini-ITX) máx.
- Sistema pode ser instalado inclusive em memórias de estado sólido (microSD por exemplo).

Utilidades: adaptador para discos
=================================

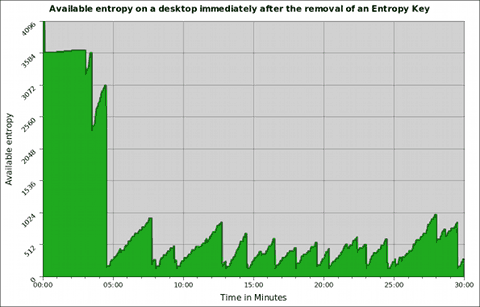
Utilidades: chave de entropia
=============================

Segurança
=========
Acesso remoto:
- Contas SSH administrativas em todos os nodos.
- Contas SSH de backup para nodos de backup.
- Contas SSH de tunelamento para nodos diversos.
Análise:
1. É importante isolar o máximo a capacidade de acesso para contas de nodos de backup ou que tunelem conexões.
2. Administradores/as precisam ter boas medidas de segurança:
- Pasta criptografada.
- Senhas e chaves seguras.
Protocolos sociais
==================
- Protocolo de Ação Coletiva: [http://protocolos.sarava.org](http://protocolos.sarava.org).
- Outros protocolos e metodologias (contabilidade, acesso à informação, relação com grupos, etc).
- Uso de um sistema de gestão de processos (trac ou similar).
.------------------->-----------------.
/ .----------<--------------<-------. \
| ' \ \
| | .------>-----. \ \
| | | \ \ \
Proposta -----> Discussão ->--. \ \ \
| ^ | \ \ \ \
| | | \ \ \ \
| `----<-----' | \ \ \
| | | \ \
`------>------ Decisão --<--' | \ \
| | | \ \
| | | | |
Atribuição de --<---' '---> Arquivamento --->---' ;
Responsabilidades ----->-------' ^ \ /
^ | ___________/ `---<-----'
| \ .'
| `--> Realização -->--.
| | | \
| | | /
`----<-----' `-----<---'
Resumo: Estratégia de gestão
============================
- Facilitar instalação, manutenção e gestão de dados.
- Manter backups em máquinas prontas para serem inicializadas.
- Manter nodos master prontos para assumirem o posto de "cabeça ativa".
Parte 6: A Confederação das Hidras Unidas
=========================================

A Confederação das Hidras Unidas
================================
- Hidra é um processo, não uma tecnologia, implementação, sistema ou serviço.
- Assim, é possível ter hidras menos sistematizadas e com diferentes formas de organização. O processo já ocorre em vários locais.
- Havendo várias hidras, se elas se integram passa a existir a Confederação das Hidras Unidas.
- Importante questão do licenciamento: AGPL 3.0 para garantir o máximo possível da disponibilização de código e documentação.
- Não é estritamente necessária a criação de uma "confederação", já que a cultura de hidras pode ser não-coordenada.
Parte 7: Nuvens e Hidras
========================
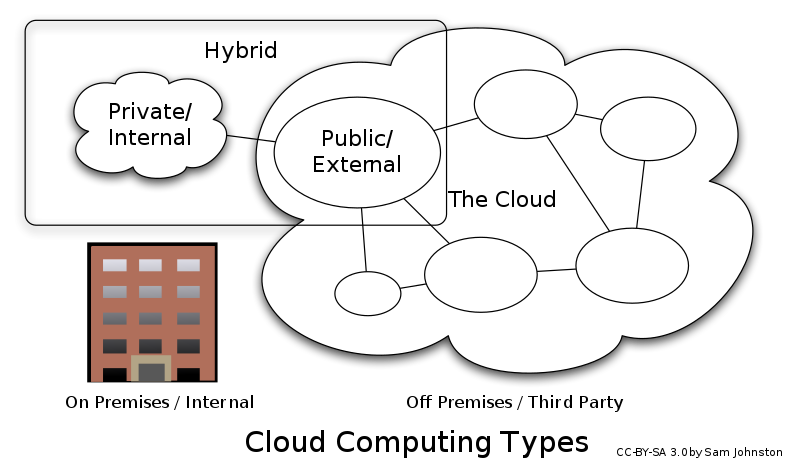
Hidras são nuvens (cloud computing)?
- Cloud computing foca apenas nas instâncias e como estas são integradas por aplicações (IaaS, SaaS, PaaS) e no seu uso sob demanda.
- Cloud computing é uma iniciativa do mercado e uma tendência à terceirização total das atividades.
- A Hidra leva em consideração a organização social que suporta a infraestrutura computacional.
- A Hidra é uma nuvem na qual certos nodos desempenham papéis determinados, porém contendo o germe de toda a organização.
- Outra classe de nuvens: botnets.
Nuvens: diagramas
=================


Tipos de nuvens
===============
Parte 8: Futuro
===============
- Hidra Saraventa: ainda em intenso desenvolvimento, porém já em estágio maduro. Falta (em agosto/2010):
- Melhoria no procedimento de bootstrap.
- Integração com DNS.
- Sistema de proxy para balanceamento de carga.
- Melhoria de procedimentos de sunsetting de sítios, plataformas e contas.
- Longuíssimo prazo, caso realizável: possibilidade de um nodo ser convertido de uma classe para outra.
- Procedimentos para suporte jurídico.
- Nodos em conexões DSL e cabo: IP dinâmico, DNS reverso, etc.
- VPN entre os nodos, Puppet Dashboard?, External node tool?
- Migrar para Linux Containers (lxc).
- Melhoria da documentação e representações gráficas do processo.
- Storage de dados distribuído.
- Hidras via Rádio.
- Hidras em outros tipos de organizações sociais.
Parte 9: Conclusões
===================
- Resolver a replicação e escalabilidade primeiro na infraestrutura (máquinas, configurações e backups), depois nas camadas superiores (CMSs, por exemplo)
- Não importa tanto se a rede é centralizada, descentralizada ou distribuída se antes de tudo ela for regenerativa. No entanto, em geral são as redes distribuídas e descentralizadas que possuem fatores de regeneração maiores do que no caso centralizado.
- Número grande de máquinas é interessante: várias podem estar sem funcionar num dado momento, mas as que estiverem funcionando podem dar conta da demanda.
- A hidra é indestrutível? Essa questão faz sentido? Positivismo, revoluções e cataclismas: o limite da hidra por ter uma relação e abertura e fechamento (autonomia dependente).
Parte 10: Referências
=====================
Referências: imagens usadas
===========================
- [http://en.wikipedia.org/wiki/File:Hydra\_04.jpg](http://en.wikipedia.org/wiki/File:Hydra_04.jpg)
- [http://en.wikipedia.org/wiki/File:Hydra001.jpg](http://en.wikipedia.org/wiki/File:Hydra001.jpg)
- [http://code.google.com/edu/parallel/dsd-tutorial.html](http://code.google.com/edu/parallel/dsd-tutorial.html)
- [http://en.wikipedia.org/wiki/File:DNS_in_the_real_world.svg](http://en.wikipedia.org/wiki/File:DNS_in_the_real_world.svg)
- [http://www.linux.org/docs/ldp/howto/Jabber-Server-Farming-HOWTO/c2sfarm.html](http://www.linux.org/docs/ldp/howto/Jabber-Server-Farming-HOWTO/c2sfarm.html)
- [http://www.autistici.org/orangebook/slides/orangebook.en.html](http://www.autistici.org/orangebook/slides/orangebook.en.html).
- [http://www.autistici.org/orangebook/slides/orangebook.en.html](http://www.autistici.org/orangebook/slides/orangebook.en.html)
- [http://perl.apache.org/docs/tutorials/apps/scale_etoys/machine_layout.png](http://perl.apache.org/docs/tutorials/apps/scale_etoys/machine_layout.png)
- [http://en.wikipedia.org/wiki/File:ICEgrid.png](http://en.wikipedia.org/wiki/File:ICEgrid.png)
- [http://www.ibiblio.org/pioneers/baran.html](http://www.ibiblio.org/pioneers/baran.html)
- [http://www1.folha.uol.com.br/folha/ciencia/ult306u442499.shtml](http://www1.folha.uol.com.br/folha/ciencia/ult306u442499.shtml)
- [http://www.tutorvista.com/content/biology/biology-iv/growth-regeneration-ageing/regeneration.php](http://www.tutorvista.com/content/biology/biology-iv/growth-regeneration-ageing/regeneration.php)
- [http://www.uni-kiel.de/zoologie/bosch/developmentalbiology.html](http://www.uni-kiel.de/zoologie/bosch/developmentalbiology.html)
- [http://www.uni-kiel.de/zoologie/bosch/developmentalbiology.html](http://www.uni-kiel.de/zoologie/bosch/developmentalbiology.html)
- [http://www.puppetlabs.com/puppet/introduction](http://www.puppetlabs.com/puppet/introduction)
- [http://docs.reductivelabs.com/guides/introduction.html](http://docs.reductivelabs.com/guides/introduction.html)
- [http://www.nagios.org/about/screenshots](http://www.nagios.org/about/screenshots)
- [http://en.wikipedia.org/wiki/File:Munin-memory-week.png](http://en.wikipedia.org/wiki/File:Munin-memory-week.png)
- [http://hoth.entp.com/output/git_for_designers.html](http://hoth.entp.com/output/git_for_designers.html)
- [http://en.wikipedia.org/wiki/Mini-itx](http://en.wikipedia.org/wiki/Mini-itx)
- [http://www.sataadapter.com](http://www.sataadapter.com)
- [http://www.entropykey.co.uk](http://www.entropykey.co.uk)
- [http://apod.nasa.gov/apod/ap010416.html](http://apod.nasa.gov/apod/ap010416.html)
- [http://en.wikipedia.org/wiki/File:Cloud_Computing_Stack.svg](http://en.wikipedia.org/wiki/File:Cloud_Computing_Stack.svg)
- [http://en.wikipedia.org/wiki/File:CloudComputingSampleArchitecture.svg](http://en.wikipedia.org/wiki/File:CloudComputingSampleArchitecture.svg)
- [http://en.wikipedia.org/wiki/File:Cloud_computing_types.svg](http://en.wikipedia.org/wiki/File:Cloud_computing_types.svg)